Author:

Callback, Promises, Async Await. We use these keywords when fetching data from an API, when creating delays or awaiting database calls, etc. But why? Why do we endorse Asynchronous patterns in the first place? Let’s find out!
 Photo by Pixabay
from Pexels
Photo by Pixabay
from Pexels
By the definition — it’s a piece of code that will start now and finish sometime in the future. An example of an Asynchronous code can be:
By default, JavaScript is a synchronous language, meaning it executes code line by line. However, it starts to behave quite differently when we add Async ingredients into the mix. Let’s see an example of that:
Here we’re using setTimeout to simulate an Async call. Its purpose is to delay the execution of the code within the callback function for a specified period of time. Since timeouts cause delays, looking at the snippet above you may think that execution will go like this:
But what will happen is this:
Weird, right? What actually happened is,
We can see that these timeouts to schedule execution rather than pausing it. What is actually happening here is JavaScript is processing Async code in the back while the rest of the code is been executed. How is this possible?
 Photo by Pixabay
from Pexels
Photo by Pixabay
from Pexels
Thread is a small set of instructions designed to be scheduled and executed by the CPU.
It all starts with a process. A process may have one or more threads. Each thread is designed to carry out a single task from start to finish.
Imagine a typical backend application that uses multithreading.
So the primary thread can create new threads every time a new request comes in.
Now that we understood why we need multiple threads, you may think that JavaScipt uses the same mechanism to process data. But, here comes the plot twist, JavaScript is single-threaded!
But why then does setTimeout or an API call not block the program execution?
 Photo by Pixabay
from Pexels
Photo by Pixabay
from Pexels
Before we answer the previous question, let’s first understand what are runtime environments. A runtime environment is what allows us to write JavaScript everywhere, be it in the browser or on the server. There are two parts we’ll discuss:
JS Engine
The Engine is in charge of converting JavaScript code into machine code. It is what allows us to
execute JavaScript on our machines.
There are few engines out there, but the most well-known one is the V8, as it powers Google Chrome,
Opera, and Microsoft Edge.
Call Stack (sometimes referred to just as a Stack) is a stack data structure that stores information about the active subroutines of a computer program. Basically, it’s a space where all of our JS code is placed. Also helps us to keep track of where we are in the code.

How the stack works is each line of code it’s pushed to the stack (bottom-up) and popped off (top-down) when executed (LIFO). The last statement is executed first, then the one before, all the way down until the stack is empty. We can verify this by running this code in debug mode.
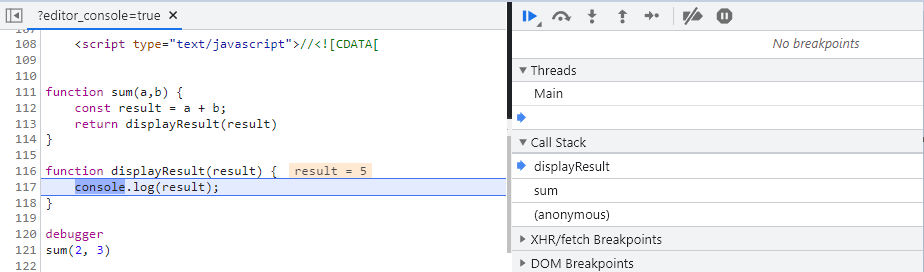
The code is sorted in reverse order as expected.
It all starts by running the main()function that is created by the engine and its purpose is to run our code. We don’t writemain()manually. Once the call stack is empty, main()will be popped off as well.
Web APIs are APIs that are built into the runtime and provide native features that can be used in a JavaScript app. These include:
Because these are not built into the language, but rather are part of the runtime, they’re not been processed by the JavaScript thread.
...
This is why when we click a button or make a network call in our frontend application, the app is still running and the screen isn’t frozen while the request is being processed. It’s running in the back, allowing our app to stay interactive.
Synchronous tasks remain on the main thread (call stack) and are executed first. Asynchronous ones go through a different process (that we’ll get to in a minute) and then get pushed to the stack and they’re executed on the thread. This is why we see “Frodo” and “Merry” printing first, while “Sam” and “Pippin” appear later
This scheduling of tasks is happening on the backend side of JavaScript as well. That’s why things like:
don’t block the execution on the main thread. Hence, why Node.js was advertised as Non-Blocking I/O.
In the case of Node.js, Web APIs are handled by Libuv library. Libuv is written in C, which is a multi-threaded language, which means that Node.js uses threads under the hood.
In the case of Deno, it uses the Rust library called Tokio. And everything else, like loops, conditions, declarations, etc, is executed on the main JavaScript thread.
...
Obviously, there is a lot going on here, so you might be wondering how is the whole process being managed?
 Photo by Engin
Akyurt
from Pexels
Photo by Engin
Akyurt
from Pexels
On the first run of our application, JavaScript creates a single thread, a single call stack, and a single instance of the Event Loop. The Event Loop is responsible for executing the code, collecting and processing events, and executing queued sub-tasks.
We can think of an Event Loop as a loop that is continuously spinning and running different operations in different phases:
1. Timers: This phase executes callbacks scheduled by setTimeout() and setInterval().
2. Pending Callbacks: Executes I/O callbacks deferred to the next loop iteration.
3. Idle, Prepare: only used internally.
4. Poll: Retrieve new I/O events and execute I/O-related Callbacks, e.g.
- API handler app.get('/', (req, res) => {})
- File system fs.readFile()
Almost all Callbacks are executed in this phase, except for Timers and Checks.
5. Check: setImmediate() callbacks are invoked here.
6. Close Callbacks, e.g. socket.on('close', ...).
We can visualize the Event Loop like this,
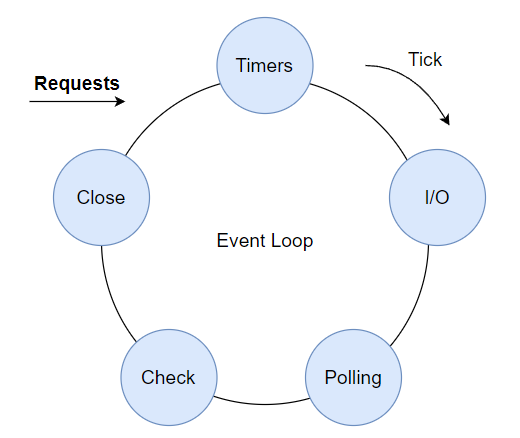
Every time a new request comes in, the Event Loop will determine to which phase it belongs and move it there. This is important to know as these phases execute in order. So if we have a Timer (setTimeout()) and I/O Callback (fs.readFile()), even if they take the same time to execute, Timer will execute first.
Note: One cycle (spin) of the Event Loop is called a Tick.
Let’s once again look back at our starting example and try to understand how the whole thing is working behind the scenes.
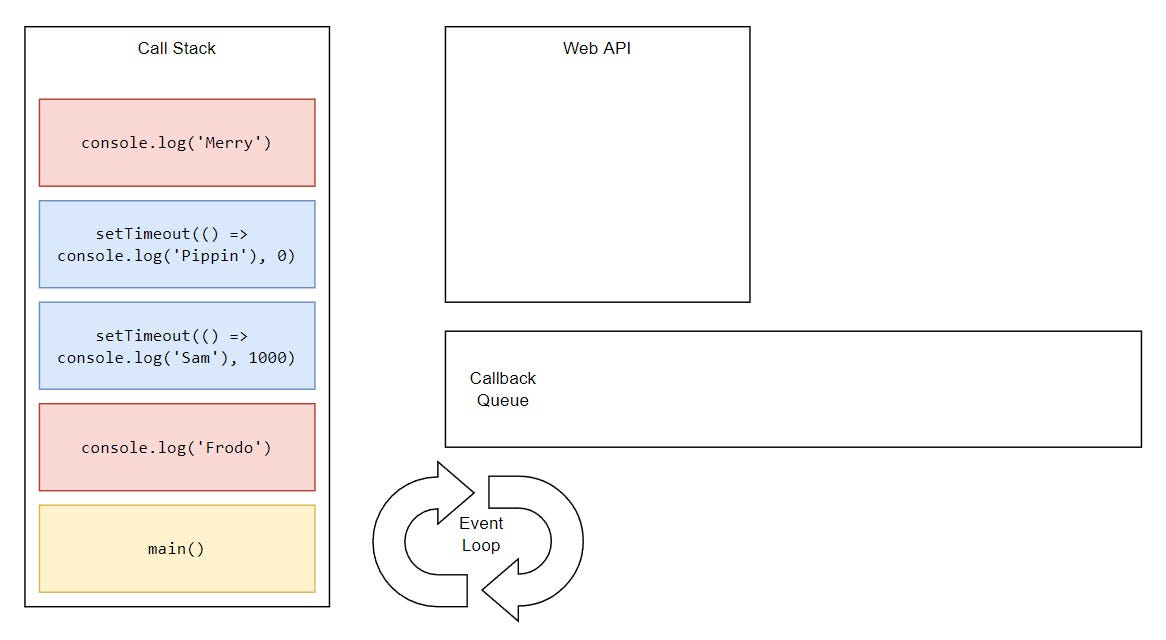
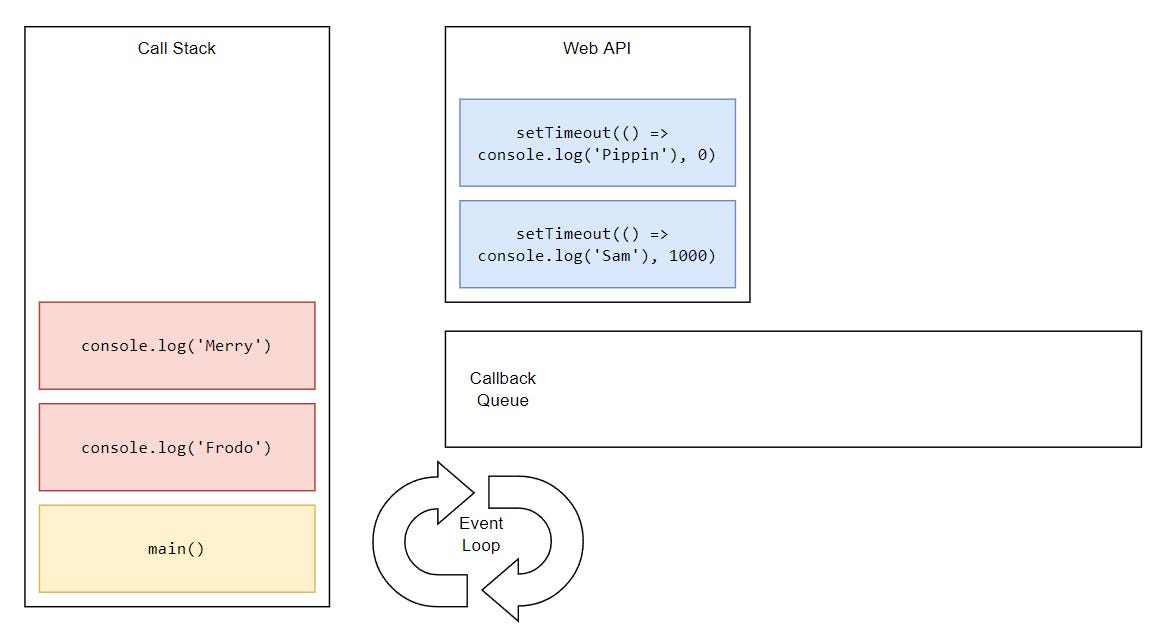
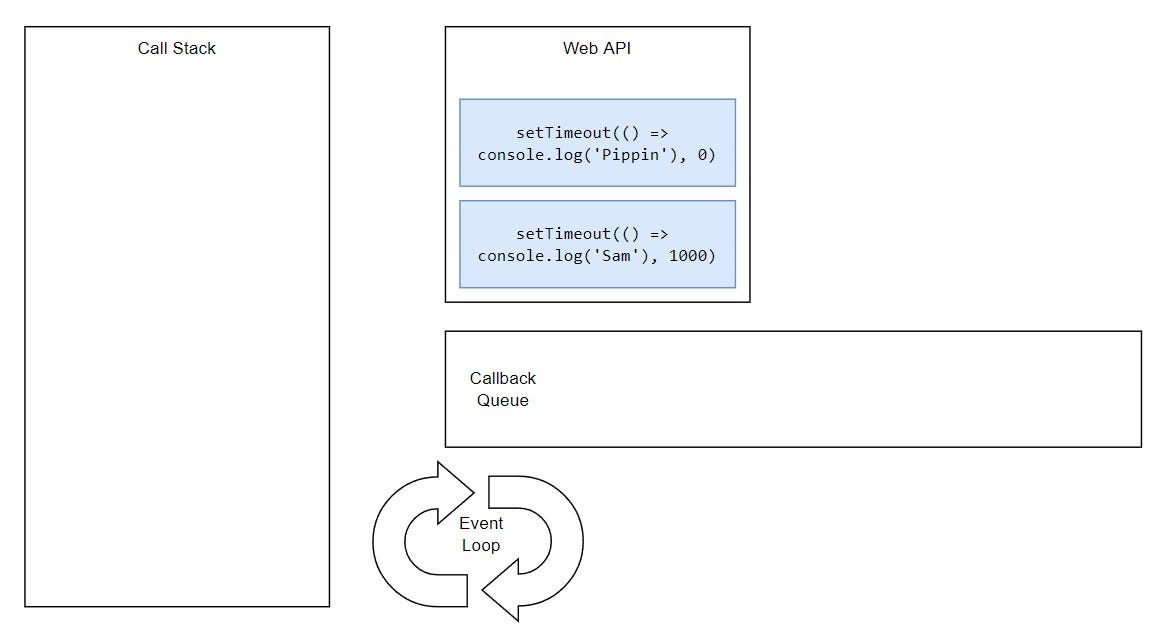
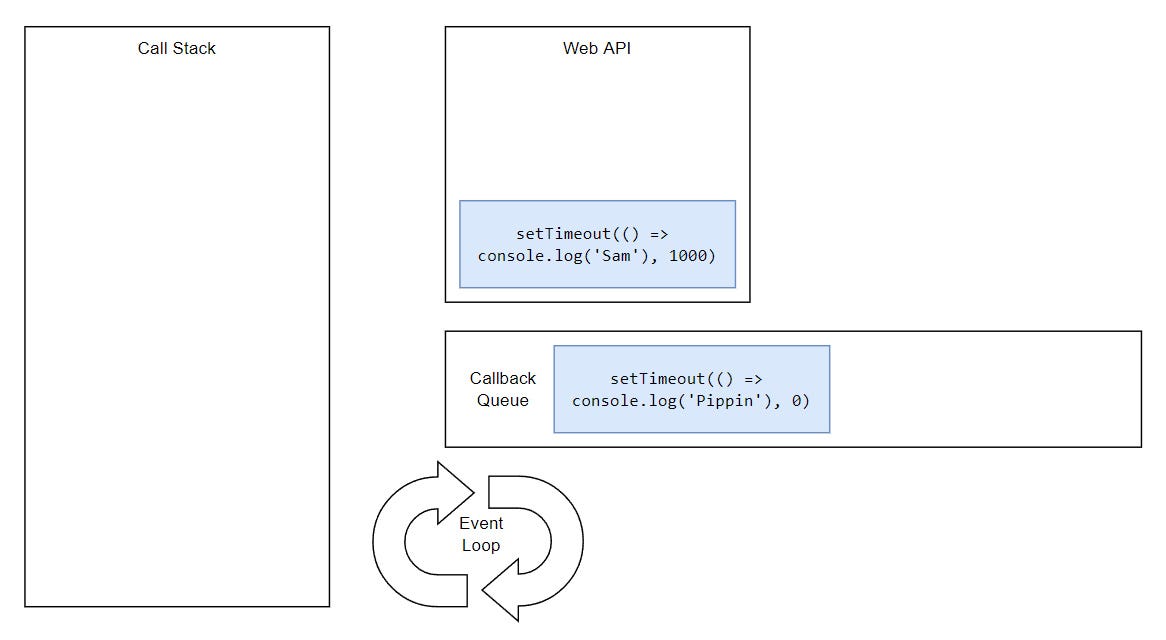
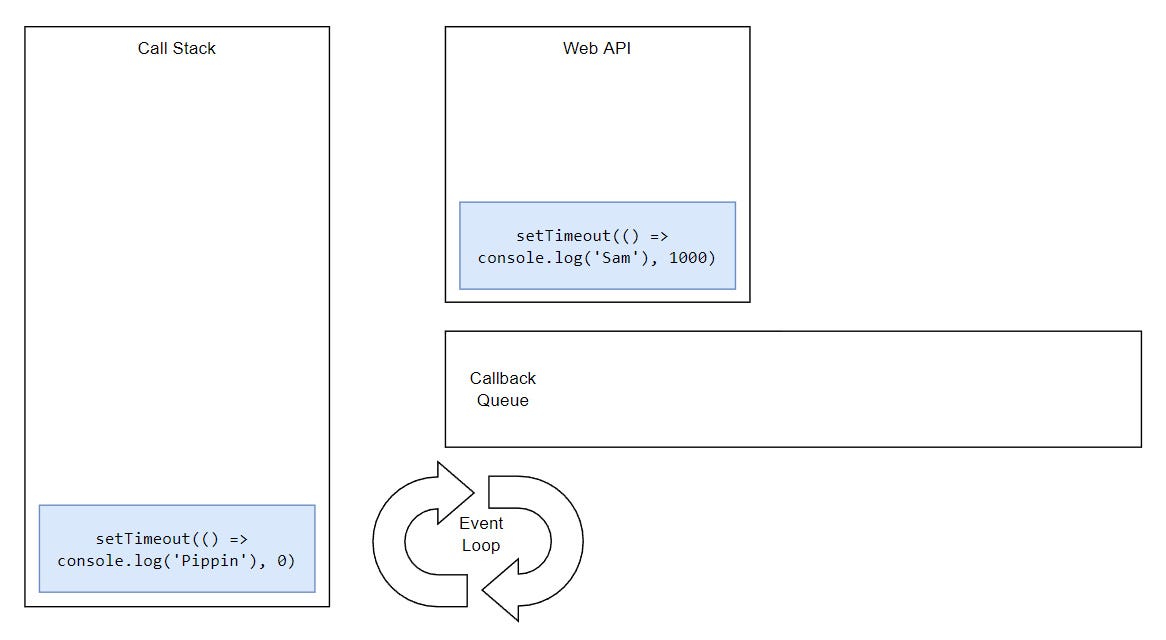
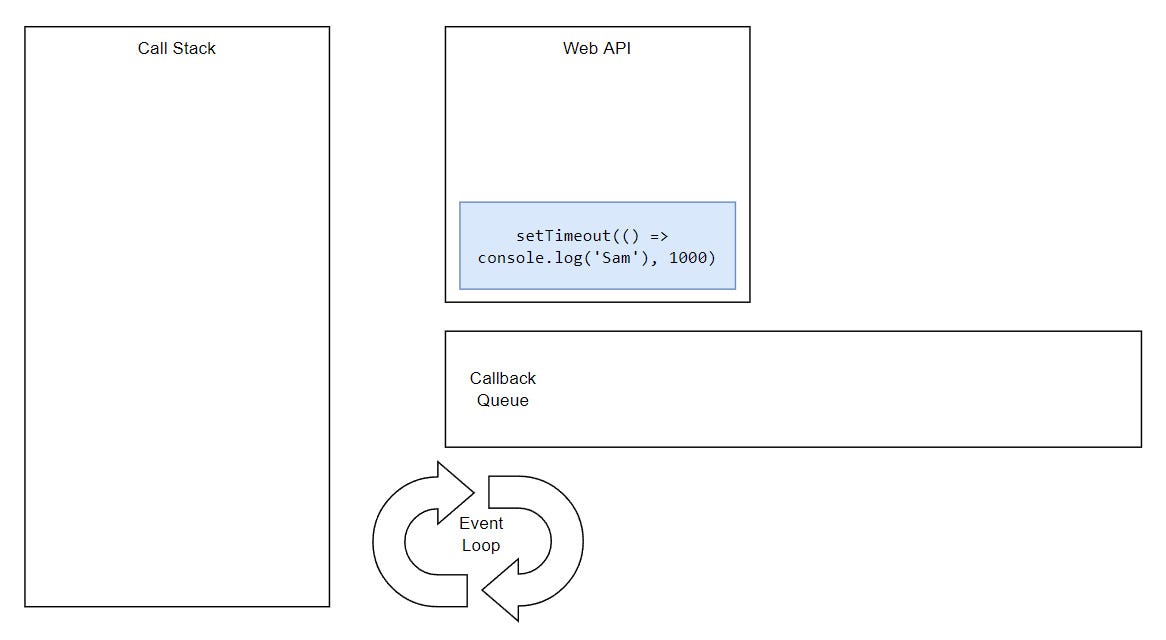
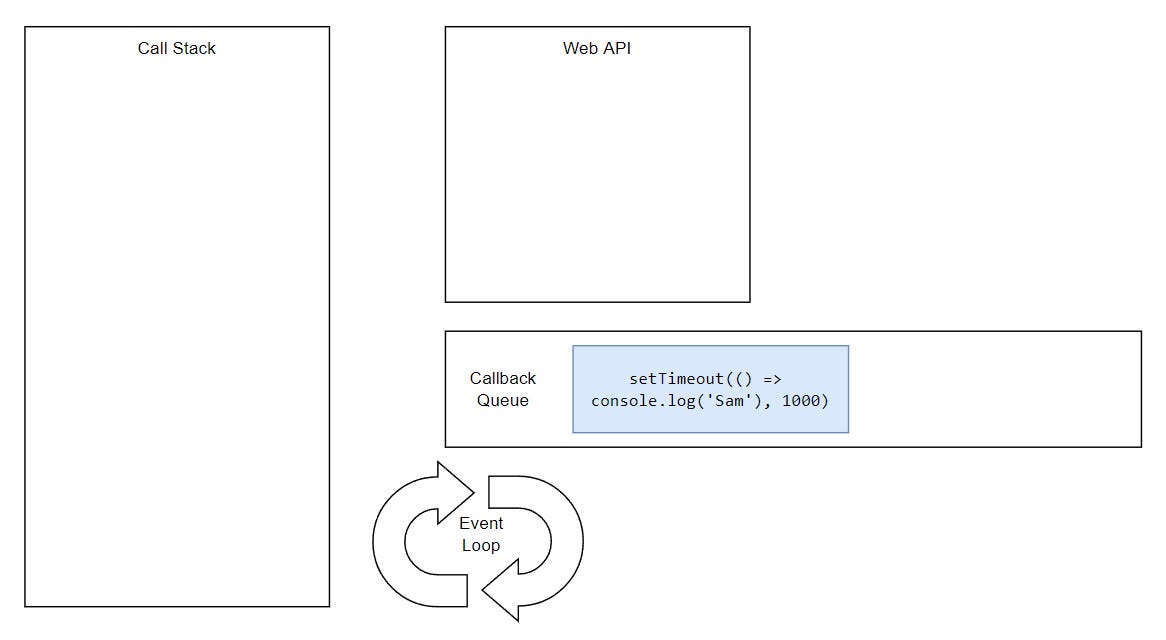

...
But, what would happen if we had two timeouts and both had the same delay?
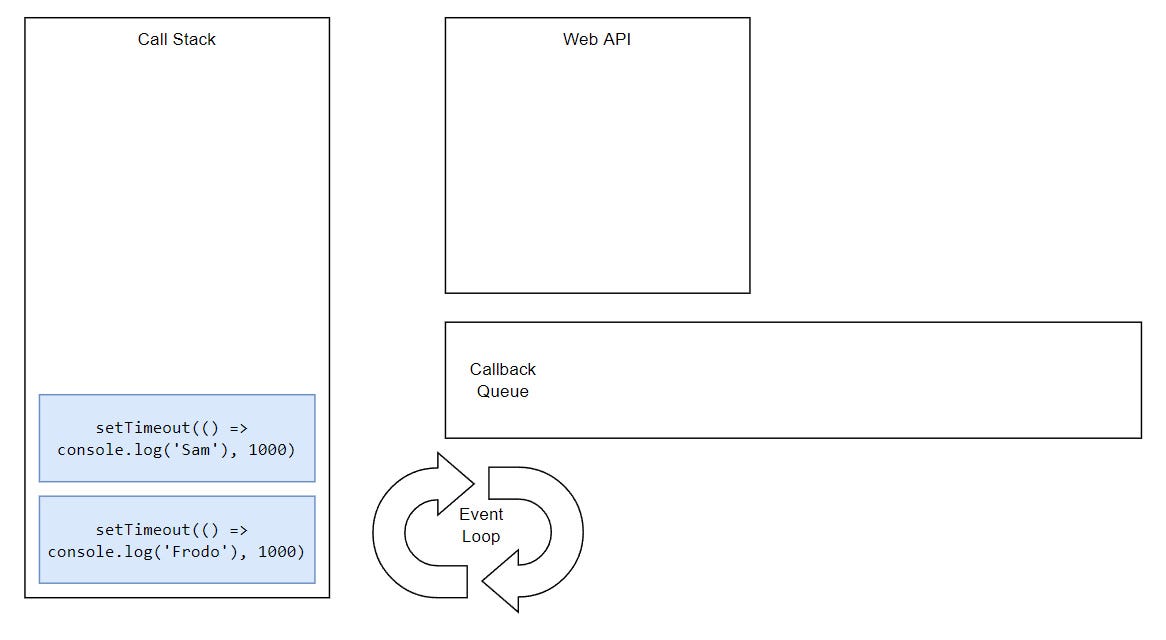
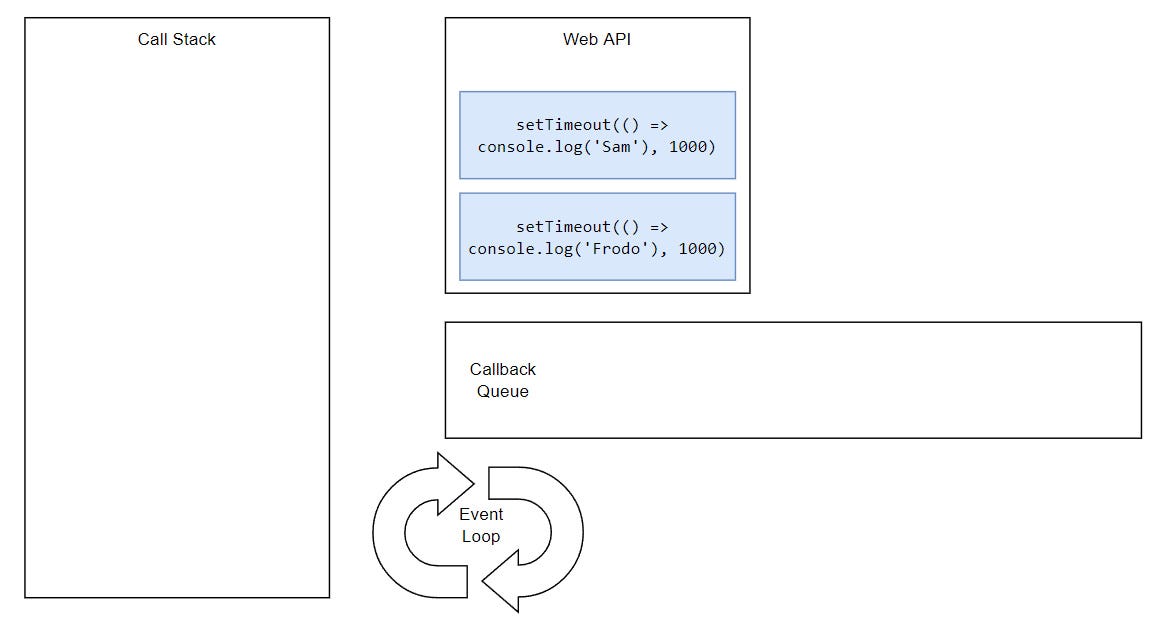
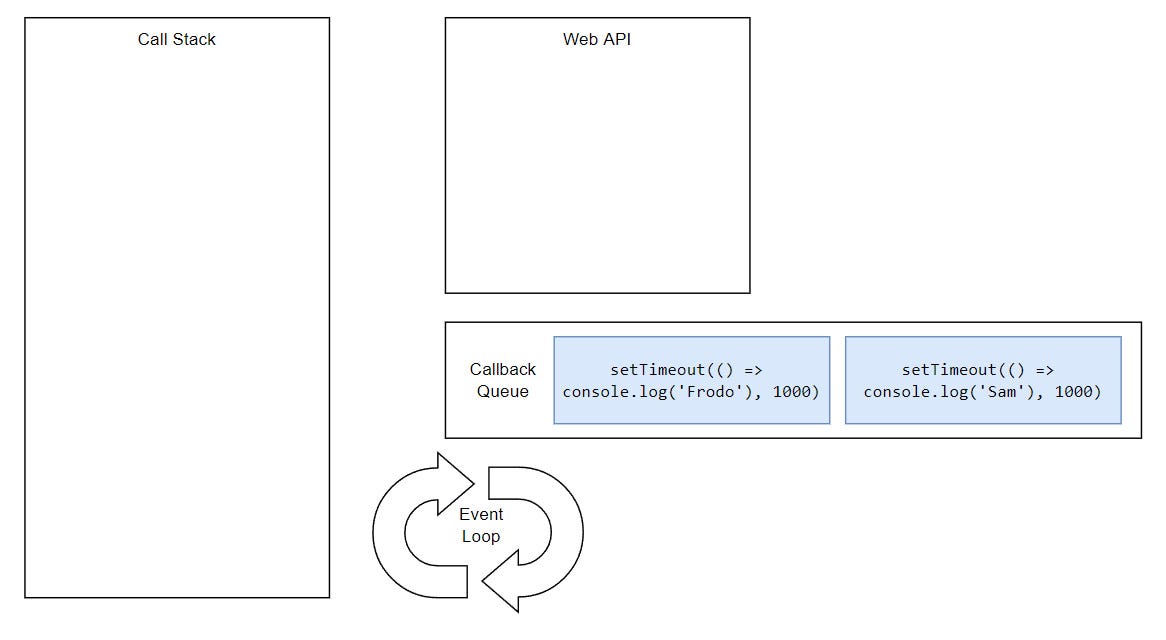
Basically, tasks execute in the order they were queued. This is happening because the Event Loop can only push one thing at the time into the stack.
So far we mostly discussed Callbacks, but what about Promises? In which phase are they executed?
ECMAScript 2015 introduced the concept of the Job Queue, which is used by Promises, queueMicrotask, and the Mutation Observer API. It’s a way to execute the result of an async function as soon as possible, rather than being put at the end of the call stack.
Any task in Job Queue (Microtask) will have greater priority than the Callback Queue (Macrotask) task.
Microtasks can be executed in each phase of the Event Loop. In fact, they have precedence.
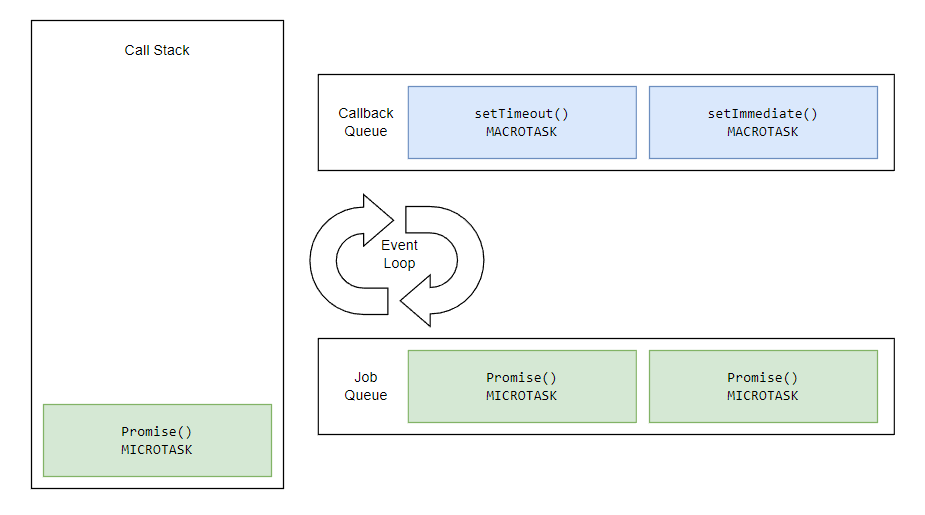
Microtasks can be executed in each phase of the Event Loop. In fact, they have precedence.
If we have a Callback and Promise in the same block, Promise will execute before Callback.
The same is true for process.nextTick()function in Node.js that takes precedence over Promises. This function is called on every tick (spin) of the Event Loop.
It’s the way we can tell the JavaScript engine to process a function asynchronously as soon as possible.
The golden rule in JavaScript says “Don’t Block the Event Loop”. This essentially suggests we use Asynchronous programming whenever possible to have better-performing applications.
Any synchronous task will block the Event Loop, as Event Loop cannot run until the call stack is empty. But did you know that Promises can block the Event Loop as well?
A Promise, being a Microtask, is capable of en-queuing other microtasks. This means that Promises will run one after another, completely disregarding operations in other phases.
The Event Loop does not move to the next task outside of the microtask queue until all the tasks inside the micro task queue are completed.
This is a problem, because we may want to read from files or perform other I/O operations that are managed through Callbacks, but due to Promise having higher priority, it will block the Event Loop, and we will never get to the point to begin processing other tasks.
To solve this, we can wrap Callback code into a Promise or search for API alternatives that use Promises, e.g.
Or avoid using microtasks where they might create a bottleneck.
Now we know that if we put Promise and Callback under the same umbrella, Promise will have precedence over a Callback. To really put it to bed, let’s see this again with nested code.
In this case, the output will be:
Queue Microtask is a new browser API that runs after the current task has completed its work and when there is no other code waiting to be run before control of the execution context is returned to the browser’s Event Loop.
Anything we put inside will be treated with priority.
It’s similar to what we were doing using setTimeout:
The only difference is that queueMicrotask will execute ahead due to the microtask queue.
The Async Await feature was added to JavaScript with ECMAScript 2017 as a way to better handle Promises. But there is a common misunderstanding about it.
There is a belief that when you put an async keyword in front of a function call in JavaScript, you turn an operation that is normally Synchronous into Asynchronous. Although that isn’t wrong, it certainly isn’t a game changer as it appears. Let me show you what I mean.
In C# API calls are synchronous by default, which isn’t much of a problem as C# is multithreaded.
We can convert this to the Async variant by using the Task class.
One would think that JavaScript functions the same, but we’ve just learned that JavaScript can run Asynchronous tasks in Callbacks (macrotasks) that have been part of the language long before Async Await.
In fact, JavaScript/Node.js will always try to execute I/O operations Asynchronously unless we specifically say otherwise.
So what’s the purpose of Async Await in JavaScript then?
Async Await is wrapper for Promises — a way to handle them in a more readable fashion and easier to maintain.
Native use of Promises
Async Await alternative
The way it works is that we put await keyword in front of the pending Promise. This works like a Promise.then() call, except that it does not require a Callback to get the output (greet).
Let’s quickly go over all the steps:
Even though Async Await makes our code look synchronous, keep in mind that this is still a wrapper for Promise, which is async. However, there is a slight difference — the Pause.
Let’s compare this to Async Await.
Because the await expression causes async function execution to pause until a Promise is settled, await won’t let loggers to complete before continuing execution. So in essence, Async Await executes before Promise.then()as it does not need to wait for the call stack to be empty.
The final gotcha with async functions in JavaScript — they always return Promises, regardless of what they contain.
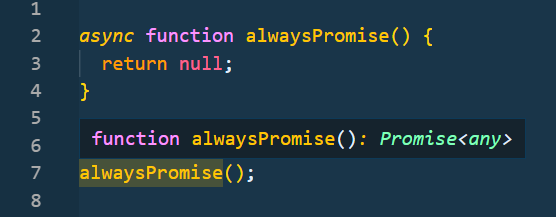 Async functions return Promise
Async functions return Promise
The output can then be handled via another await or Promise.then().
Async Await has found its way into other branches.
Just like with this reading data from file example.
Before
After
JavaScript delegates Asynchronous tasks from the main thread to the Web API. That’s why async requests don’t block the program execution.
The same applies to the backend side of JS. DNS requests are asynchronous. When a new request comes in, it’s delegated to the Web API. DB calls (I/O operations) are also non-blocking, so the main thread is free to take other requests while Liuv threads are processing I/O requests in the back.
The Event Loop manages the scheduling of tasks. It consists of multiple phases, each in charge of processing different operations.
We have microtask and macrotask queues. Each has a series of APIs associated with them.

Microtasks have priority, and thus are executed beforehand, but block the Event Loop.
Async Await is a wrapper for Promise functions that let us write async code in a synchronous manner.
 Photo by Rabia
from Pexels
Photo by Rabia
from Pexels
Now let’s go over the ups and downs of using Async code.
Async calls are actually slower than synchronous ones because it takes time to process them, as well as take a round trip through the Event Loop.
Writing and debugging Async code is hard. You may have heard of a term called Callback-Hell. It’s a series of deeply nested functions that are dependent on one another and are very hard to read and maintain.
There are downsides to newer APIs as well. Since functions marked with the async keyword return a Promise, if we have a series of nested function calls, each needs to be marked as async to be able to use the await keyword within. Otherwise, we’re prone to use Promises.
We know that synchronous operations are executed on the main thread. Since JavaScript uses only a single thread to handle these operations, our app is going to run line by line and when it encounters a loop, it will pause.
That’s why JavaScript is not good for long-running blocking operations, like crunching numbers. Since all of its blocking execution is on a single thread, long-running operations cannot be delegated to other threads, meaning that our app will wait and block everything else.
This is probably the biggest downside of JavaScript, but there are some feasible solutions recently added to the language like Web Workers API.
Async API is constantly been improved with new versions of ECMAScript. It started with Callbacks, then moved to Promises, and then Async Await. The Promise API recently brought new additions like Promise.any(), Promise.race() and Promise.all().
Then there is also Top-Level Await.
JavaScript comes with a list of tools to work with Asynchronous data, native ones like:
as well as third-party ones:
Instead of having imports on top of the file, the modules can be imported dynamically. The idea behind this is to use Asynchronous calls to import modules (files) after a certain action occurs, like a button click.
As we established so far, Async code is processed outside the main thread and thus does not block the thread.
Nevertheless, now we know why it’s important to use the Async patterns in JavaScript whenever possible. Many popular frameworks and libraries on NPM use Async patterns automatically, although some of the older ones still work only with Callbacks. So it’s a both hit and miss.
 Photo by cottonbro
from Pexels
Photo by cottonbro
from Pexels
Before wrapping up let’s say a word or two about the new JavaScript Workers API. Web Workers make it possible to run a script operation in a background thread separate from the main execution thread of a JavaScript application.
Its purpose is to separate sync tasks into smaller workers, so that long-running operations (such as loops) are not blocking the main thread.
It works just as we’d expect. The main JavaScript thread can send data to the worker threads. Each worker processes a task sent by the main thread and returns it upon completion.
Node.js also has its own variant with the use of worker threads built-in module.
However, these are not efficient for async tasks. The standard (Event Loop) way is much better to handle async tasks.
Even with all the powers of the runtime, we are still bound by the thread pool size. The Libuv library allows us to process only a few I/O operations at once, due to Libuv having up to 4 threads in the thread pool.
We can increase this number to up to 1024 threads by setting the following environment variable on application startup:
But keep in mind that bigger isn’t always better. Try to find the optimal thread pool size according to the performance of your machine. The usual approach is to set it to equal the number of logical cores of your PC.
We can verify that by importing the OS module (that is native to Node.js), then call the os.cpus() (that returns an array) and then print the length of it:
Then we can set the thread pool size, either in the .env file or dynamically (in our main JS file):
 Photo by Johannes Plenio
from Pexels
Photo by Johannes Plenio
from Pexels
To tie things with a bow, JavaScript leverages Async code to execute away from the main thread. This pattern is great as it does not block the execution of the program, but it comes with some downsides as well.
Overall, it’s an amazing feature that makes JS stand out in the crowd.
In part 2 we’ll dive deeper into practical examples with Fetch API, Observables, Handling errors, and more.
Author: